In this article, we'll give a basic overview of SQL, how it's used, and useful SQL shortcuts for developers. We'll also go over basic SQL queries, functions, joins, and subqueries. Then, at the end of the article, you can grab a copy of our handy SQL cheat sheet. But first, let's get started with some background information on SQL.
Back to topWhat Is SQL?
SQL is a domain-specific language used for database and stream management.
SQL (originally SEQUEL) was developed in the 1970's by Raymond Boyce and Donald Chamberlin, and has become one of the most popular database DSLs (domain specific language) in use. The open-source database implementation, MySQL, is available in both free and paid editions:
- MySQL Community Edition (Free)
- MySQL Standard Edition (Paid)
- MySQL Enterprise Edition (Paid)
- MySQL Cluster CGE (Paid)
Back to topDownload the 2021 Java Developer Productivity Report for up-to-date information on Java languages.
Using SQL (Structured Query Language)
Chances are you're using either a relational database, where the data is organized into tables of entities, or a NoSQL database, where data is organized into key-value stores, document stores, column-oriented databases, or graph databases. In microservices applications, you're probably using both, so it's useful to know how to use both SQL and NoSQL.
To communicate to a relational database, you'll use the structured query language, SQL. SQL is a great language, designed to manage complex queries in a declarative form. When writing SQL, you will focus on the data you want to fetch, rather than how you want to fetch it. The commands in SQL are called queries and there are two main types of basic SQL queries:
- Data definition queries—the statements that define the structure of your database, create tables, specify their keys, indexes, and so on.
- Data manipulation queries—what you typically think of when you talk about SQL: select, update, insert operations etc.
In our MySQL query cheat sheet, we'll mostly look at the data manipulation queries and try to explain how you want to use them.
Back to topBasic SQL Queries (Commands)
Data manipulation queries are used to retrieve the data from the database, and create or update the records in it. To retrieve the data, you query it, starting your command with the SELECT clause.
When you think of your data in a relational database, you should think in terms of set theory—you have the description of the entities in a multidimensional space, where the columns in the tables correspond to the dimensions and the rows in the tables are the data points in that space.
When you use the SELECT query, you essentially specify the projection of the data point onto a certain multidimensional space: which dimensions to include in the projection is set by the query. Below is the typical example of an SQL SELECT query:
SELECT col1, col2, col3, ... FROM table1
WHERE col4 = 1 AND col5 = 2
GROUP BY …
HAVING count(*) > 1
ORDER BY col2
You tell the database which columns from which tables you want. Then you restrict which data points to include in this projection. That is done with the WHERE clause. The rows that do not satisfy the conditions you write in the WHERE clause are omitted from the result set.
On top of that, you can group the related rows using the GROUP BY clause. For example, you can aggregate the rows that belong to the same type, like the employees of the department. You can enhance your SELECT statements with additional modifiers, for example, asking for DISTINCT entries will return you a results set with unique rows. And there are several very useful predicates you can use in a WHERE clause. The most frequently used ones are:
BETWEEN a AND b—filter the entries that do not belong to a range. This works well when you are dealing with dates, or numbers that represent something real, like a salary. It also works on text fields too.LIKE— wildcards in text. You can use the wildcard '%' to specify unknown characters in the beginning and at the end of the column, '_' for a single character.IN (a, b, c)—filter the values that do not belong to a given set. This particularly works well, when you provide types for the entries or statuses. This tends to be used when you use a subquery to fetch the data and then operate on that results set.
Data Manipulation Queries in SQL
Now we’ve covered the basics of retrieving data, the following commands will help you update the entries in your tables and create new rows. To update a table, you use the UPDATE statement, and specify which columns you assign new values to.
UPDATE table1 SET col1 = 1 WHERE col2 = 2
This is pretty straightforward, just don't forget to limit the values you want to update. If you don't specify the WHERE clause, you will update all the rows in the table and that is probably not what you wanted to achieve.
Additionally, you can update the values dynamically using the data fetched by a SELECT. However, we omitted that from the SQL cheat sheet PDF because it’s not a use case you typically find on the application side of the project.
To add new data into the tables, you’ll need to use the INSERT statement. Its syntax is also pretty understandable from looking at the command. You just need to specify the data and map which values you want to assign to which columns in the table. Or you can batch insert the values that are returned by a SELECT query.
INSERT INTO table1
(id, first_name, last_name)
VALUES (1, 'Rebel', 'Labs');
INSERT INTO table1 (id, first_name, last_name)
SELECT id, last_name, first_name FROM table2
Armed with UPDATEs and INSERTs you are pretty dangerous to any database now, so don't forget to limit the update range with a WHERE clause. Moreover, typically, writing into a database requires a transaction, so if you start one and execute an UPDATE, review the results and commit the transaction.
Back to topTry JRebel
Want to see how much time JRebel can save you? Try it free for 10 days with a JRebel trial.
Working With Multiple Tables: SQL Joins and SQL Subqueries
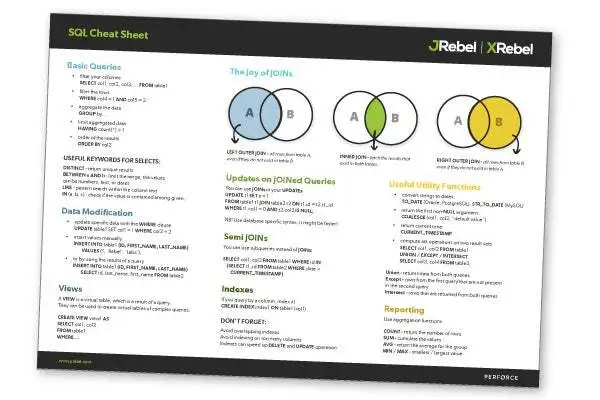
When you master simple queries, you're ready to make the database a really powerful ally. To do so, you need to fetch the data from several tables at the same time, relating the entries from one table to the corresponding rows in another. This is where you'd use a JOIN. A JOIN clause is a part of a SELECT statement; it allows you to specify multiple tables for data retrieval.
The syntax of a JOIN query is the following:
SELECT … from TABLE table1 JOIN table2 ON table1.id = table2.t1_id
You just specify the tables to join and based on which columns to find what rows correspond to each other. There are several types of JOINs, but here are three most frequently used.
| JOIN | Action |
INNER JOIN | Fetch the results that exist in both tables |
LEFT OUTER | Fetch all rows from the table A, even if they do not exist in table B so that the result set will have half-populated wors |
RIGHT OUTER | Fetch all rows from table B, even when the corresponding data in table A are absent |
When you don't know how to JOIN the tables correctly, you can use subqueries instead. A subquery is a SELECT query specified in the body of another:
SELECT col1, col2 FROM table1 WHERE id IN
(SELECT t1_id FROM table2 WHERE date > CURRENT_TIMESTAMP)
Subqueries work best when combined with the IN clause in the outer select. Typically you'll fetch the ids that correspond to the entries you want in the subquery and process them on the outer level. Besides just fetching the data, JOINs can make updating your data easier. Indeed, you can use the JOIN clause in the UPDATE query and filter which entries to update based on the data in the joined tables.
UPDATE t1 SET a = 1
FROM table1 t1 JOIN table2 t2 ON t1.id = t2.t1_id
WHERE t1.col1 = 0 and t2.col2 is NULL;
Even despite the restrictions (like you can only update one table this way, not both, and that the rows have to be unambiguously identifiable for this to work) this approach is quite useful to know about. Also, make sure to check if your database supports a special syntax for using joins in the update statements, as it will likely improve your performance.
Back to topUseful SQL Functions to Remember
There is one more thing, on top of querying the values that sit in the database, you can specify the functions that will transform those values into something more useful. There are quite a few of these, and you can write your own utility functions. However, here's a taste of what you can expect from any database.
| SQL Function | Action |
| TO_DATE | converts a string to date. SQL result set is typed, so if you need to use a BETWEEN clause, you'd need to convert your string dates to proper date types. |
| COALESCE | return the first non-NULL results, use it like COALESCE(col1, 'default value') when querying from the columns that can contain NULLs. |
| CURRENT_TIMESTAMP | returns the current time on the database server. |
| COUNT | an aggregate function that returns the number of rows in the results set. |
| SUM | an aggregate function to cumulate the values in the results set. |
| AVG | an aggregate function to compute the mean average of the values in the results set. |
| MIN / MAX | aggregate function to return the smallest / largest value among the results. |
On top on that, you can use the set operations on the returned results. You can use UNION to append the results of one query to another:
SELECT col1, col2 FROM table1
UNION
SELECT col3, col4 FROM table2;
The UNION operation will not allow the duplicates, UNION ALL would append all the results even if there are duplicate rows. There is also the EXCEPT operation which will return the difference between the result sets and INTERSECT for finding the intersections of the results.
Download the SQL Cheat Sheet PDF
Download and print out this SQL cheat sheet so you can use it whenever you need it. To get full the explanations and details of the content in the SQL cheat sheet, continue reading this blog post!
Final Thoughts
We've talked a lot about the basic SQL commands, including how different joins work and when to substitute them with a subquery. We also looked at a number of useful utility functions and how to perform set operations on the results of your queries. If you're looking for additional Java cheat sheets, be sure to check out our Java cheat sheet collection.
Try JRebel
Want to see how much time JRebel can save you? Try it free for 10 days with a JRebel trial.
Note: This post was originally published on June 29, 2016 and has been updated for accuracy and comprehensiveness.